Evaluating an Agent
Learn how to use datasets and LLMs as a judge to create a robust evaluation system for your AI agents.
Evaluating your AI agents in a repeatable way is important for ensuring they meet quality standards, and that you can compare different versions of your agent over time.
Using Datasets to Evaluate Your Agents
A dataset is a collection of test inputs (and optionally expected outputs) that you use to evaluate your agent. Think of it like a standardized test - the same set of questions you run against different versions of your agent to see how they perform.
Datasets give you a consistent benchmark to compare different versions of your agent and ensure important use cases always work correctly.
Selecting a Dataset Type
When creating datasets for agent evaluation, you can choose between two main approaches depending on your use case:
Input and Expected Output Datasets
These datasets include both the input and the expected output for each test case. In cases where there is only one correct output (ex: math problems, classification tasks), your evaluation process simply consists of comparing a completion's output to the correct output to determine the quality of a given version. This can be done by utilizing a script to check if they're identical (recommended) or you can manually review each completion created when the dataset is run by looking at your agent's completions on the AnotherAI web app.
When there is more than one correct output (ex: creative writing, analysis tasks), but you still want to include the expected output in your dataset, it can be useful to use LLM-as-a-judge to evaluate the quality of the output. In those cases, the LLM judge compares the actual output against the expected output to evaluate how well they match, considering factors like semantic similarity, completeness, and accuracy.
Examples of good use cases for input and expected output datasets:
- Solving math problems
- Data extraction tasks
- Classification tasks
Example Dataset: Input and Output with Exact Match Expected Output
{
"dataset_name": "customer_support_exact_match",
"test_cases": [
{
"id": "support_001",
"input": {
"variables": {
"customer_message": "I've been waiting 3 weeks for my refund!",
"order_id": "ORD-12345"
}
},
"expected_output": {
"response": "I sincerely apologize for the delay with your refund. I can see that your refund for order ORD-12345 was processed on our end but may be delayed by your bank. Refunds typically appear within 5-7 business days. I'm escalating this to our finance team for immediate review. Your case number is #CS-98765. We'll email you within 24 hours with an update.",
"case_created": true,
"escalated": true
}
},
{
"id": "support_002",
"input": {
"variables": {
"customer_message": "The product arrived damaged and I need a replacement",
"order_id": "ORD-67890"
}
},
"expected_output": {
"response": "I'm so sorry to hear your product arrived damaged. That's definitely not the experience we want you to have. I've initiated a replacement for order ORD-67890 which will ship within 24 hours via express shipping at no extra cost. You'll receive a prepaid return label via email to send back the damaged item. No need to return it before receiving your replacement.",
"replacement_initiated": true,
"return_label_sent": true
}
},
{
"id": "support_003",
"input": {
"variables": {
"customer_message": "How do I track my order?",
"order_id": "ORD-11111"
}
},
"expected_output": {
"response": "You can track order ORD-11111 using this link: track.shipping.com/ORD-11111. Your order is currently in transit and expected to arrive by Thursday, November 15th. You'll receive a notification when it's out for delivery.",
"tracking_link_provided": true,
"delivery_date": "2024-11-15"
}
}
]
}Example Dataset: Input and Output with Criteria-Based Expected Output
{
"dataset_name": "customer_support_criteria",
"test_cases": [
{
"id": "support_001",
"input": {
"variables": {
"customer_message": "I've been waiting 3 weeks for my refund!",
"order_id": "ORD-12345"
}
},
"expected_criteria": {
"must_include_topics": ["apology", "refund_status", "timeline", "next_steps"],
"tone": "empathetic_professional",
"max_word_count": 150,
"includes_case_number": true,
"offers_escalation": true
}
},
{
"id": "support_002",
"input": {
"variables": {
"customer_message": "The product arrived damaged and I need a replacement",
"order_id": "ORD-67890"
}
},
"expected_criteria": {
"must_include_topics": ["apology", "replacement_process", "shipping_timeline"],
"tone": "empathetic_professional",
"max_word_count": 150,
"includes_return_instructions": true,
"offers_expedited_shipping": true
}
},
{
"id": "support_003",
"input": {
"variables": {
"customer_message": "How do I track my order?",
"order_id": "ORD-11111"
}
},
"expected_criteria": {
"must_include_topics": ["tracking_information", "delivery_status", "estimated_arrival"],
"tone": "helpful_friendly",
"max_word_count": 100,
"provides_tracking_link": true,
"mentions_notifications": true
}
}
]
}Input-Only Datasets
These datasets contain only inputs without predefined expected outputs. Evaluation relies on LLM-as-a-judge (recommended) or human reviewers to assess quality as there is no single correct output. This approach is much better for agents that can have multiple valid outputs for a given input.
Examples of good use cases for input-only datasets:
- Creative writing
- Content summarization
- Analysis tasks
Example Dataset: Input-Only
{
"dataset_name": "customer_support_quality_only",
"test_cases": [
{
"id": "support_001",
"input": {
"variables": {
"customer_message": "I've been waiting 3 weeks for my refund!",
"order_id": "ORD-12345"
}
}
},
{
"id": "support_002",
"input": {
"variables": {
"customer_message": "The product arrived damaged and I need a replacement",
"order_id": "ORD-67890"
}
}
},
{
"id": "support_003",
"input": {
"variables": {
"customer_message": "How do I track my order?",
"order_id": "ORD-11111"
}
}
}
]
}Populating Your Evaluation Dataset
While there is no one-size-fits-all way to build a dataset, there are a few common ways to collect content for your dataset:
From User Feedback
When users report issues with your agent's outputs, these completions become valuable test cases because they represent a case that your agent is not handling well but should. To add the content of a completion to your dataset:
- Locate the completion in AnotherAI
- The exact process for this step will vary depending on how your received the feedback that the completion had an issue.
- Open the completion details and copy the completion ID
- The completion ID is location in the top right corner of the completion details modal.
- Paste the completion ID into your AI coding agent's chat and ask them to add the completion to your dataset.
- Your AI agent will be able to convert the completion content into the format of your existing dataset entries.
From Production Data
Using data from production completions instead of mocked data ensures that you're testing real-world scenarios. AnotherAI logs all completions from your agents, so you can easily review past completions for important cases to add to your dataset.
You can browse past completions from your in the AnotherAI web app:
- Go the anotherai.dev/agents
- Locate the agent whose completions you want to review
- Select the agent and scroll down it's page
- You'll be able to see some of the recent completions immediately, but for a full list, select "View all completions"
Evaluating the Results of Running Your Dataset
To evaluate your agent's outputs from running your dataset, you have two approaches:
- Deterministic evaluation (using code)
This approach is best when there is one correct, expected output for each input. In these cases you can write a simple script to compare the actual and expected outputs and run the script to evaluate the results.
Types of agents that can usually be evaluated using deterministic evaluation:
- Math problems:
2 + 2 = 4(exact match) - Data extraction: Extracted JSON must match expected structure
- Classification: Output must be one of specific categories
- LLM-as-a-judge (automated)
Many agents don't have just one correct answer, though. When multiple outputs could be considered correct, you cannot evaluate deterministically with code. In these cases we recommend building an LLM-as-a-judge system to evaluate the results.
Types of agents that can usually be evaluated using LLM-as-a-judge:
- Text generation: Two different summaries can both be correct even with different wording
- Creative writing: Many valid ways to write the same content
- Analysis tasks: Different interpretations can be equally valid
For example: If generating a product description, "This comfortable blue shirt is perfect for casual wear" and "A relaxed-fit blue shirt ideal for everyday occasions" are both correct despite being completely different text. You need LLM as a judge to evaluate if both capture the key product features correctly.
Handling Complex Evaluations with LLMs as a Judge
LLM-as-a-judge is recommended when you cannot evaluate deterministically with code using equality checks. This style of evalution uses one AI model to evaluate the outputs of another, thus taking advantage of LLM's ability to reason and deduce correctness based on previous examples or criteria instead of a strict equality check.
Key Benefits
- Scalability: Evaluate hundreds or thousands of outputs automatically
- Consistency: Apply the same evaluation criteria uniformly using a single judge model
- Structured Feedback: Get detailed scores and explanations for each criterion
- Continuous Monitoring: Track quality over time as you iterate
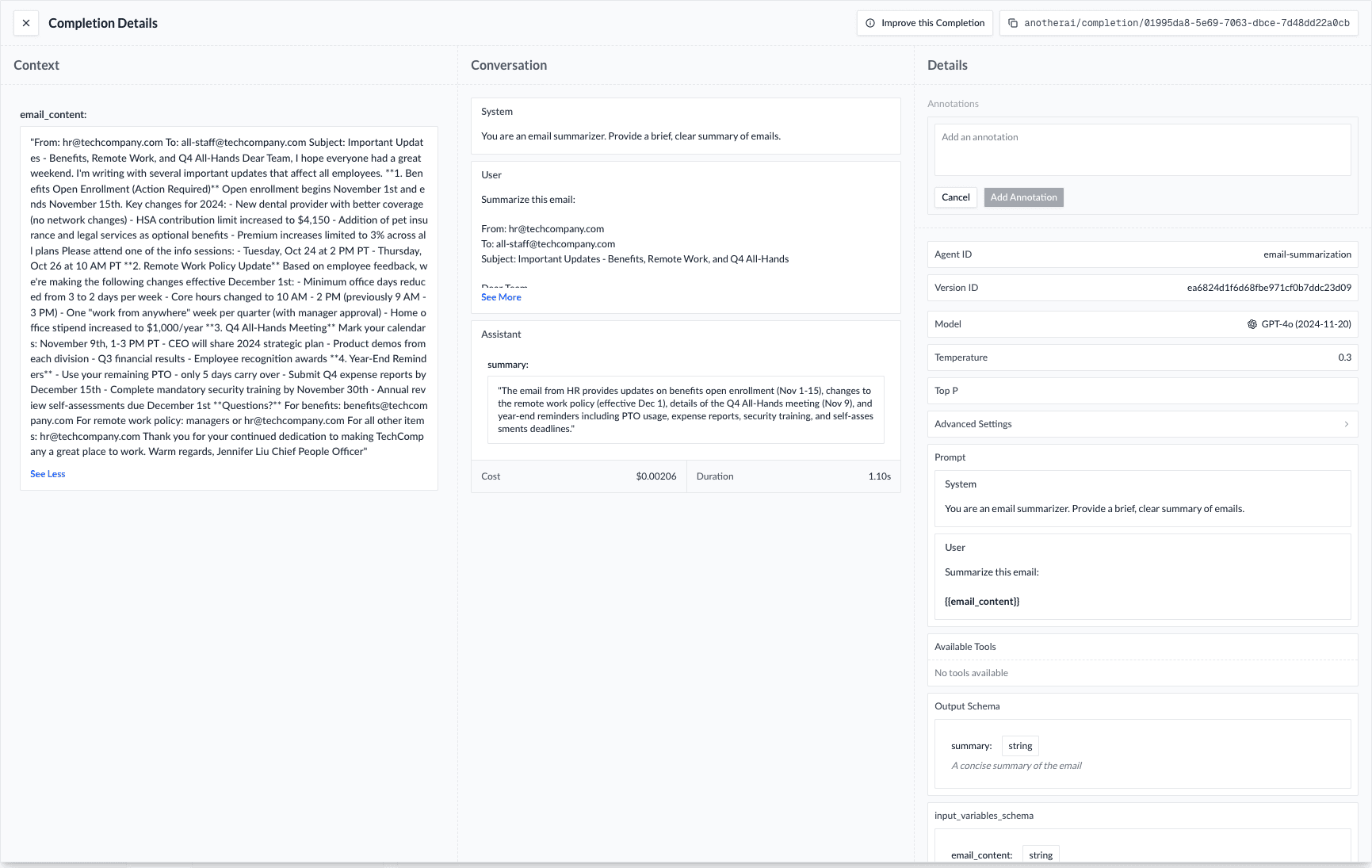
Example: Email Summarizer Evaluation
Let's walk through evaluating an email summarization agent. In this example, our agent:
- Takes an email as input
- Returns a summary
Decide on Your Dataset
Before evaluating, you need to make sure you have a robust dataset (we generally recommend at least 20 test inputs, but the number can be much higher depending on your use case). See Build Your Evaluation Dataset to learn more about this process
Example Dataset Structure: For this example, we'll use an Input-Only Dataset since there are multiple valid ways to summarize each email. Each test input would be structured as such:
// Input-only dataset
{
"id": [test input id here],
"email_title": [email title here],
"email_body": [email body here]
}Create the Judge Agent
Define evaluation criteria and scoring structure. You can ask your AI coding agent:
Create an evaluation agent for anotherai/agent/email-summarizer that evaluates outputs
on completeness, accuracy, clarity, and conciseness. Each criterion should be scored
1-10 with explanations.The key points to clarify in your request are:
- What dimensions of the output do you want evaluated? (In the case above, completeness, accuracy, clarity, and conciseness)
- How do you want them evaluated? (In the case above, 1-10 with explanations)
Create the Evaluation Pipeline
Define the pipeline functions that will evaluate your agent across multiple models. Ask your AI coding agent:
Create an evaluation pipeline that:
1. Runs anotherai/agent/email-summarizer on each test email in @email-summarizer-dataset.json
2. Uses the @email-judge-agent.py to score each summary
3. Sends the scores as annotations to AnotherAI
4. Calculates average scores to compare model performanceRun Evaluation and Analyze Results
Execute the evaluation pipeline and analyze the results. Ask your AI coding agent:
Create a script that runs @email-evaluation-pipline.py on gpt-4o-mini and gpt-4.1-nano-latest.
Load the dataset from @email-summarizer-dataset.json and show me the average scores and success rates for each model.This prompt and subsequent code will:
- Generates email summaries using the specified models
- Run the judge agent to evaluate each summary
- Store the evaluation scores as annotations in AnotherAI
Here's an example of what the evaluation results from LLM-as-a-judge might look like:
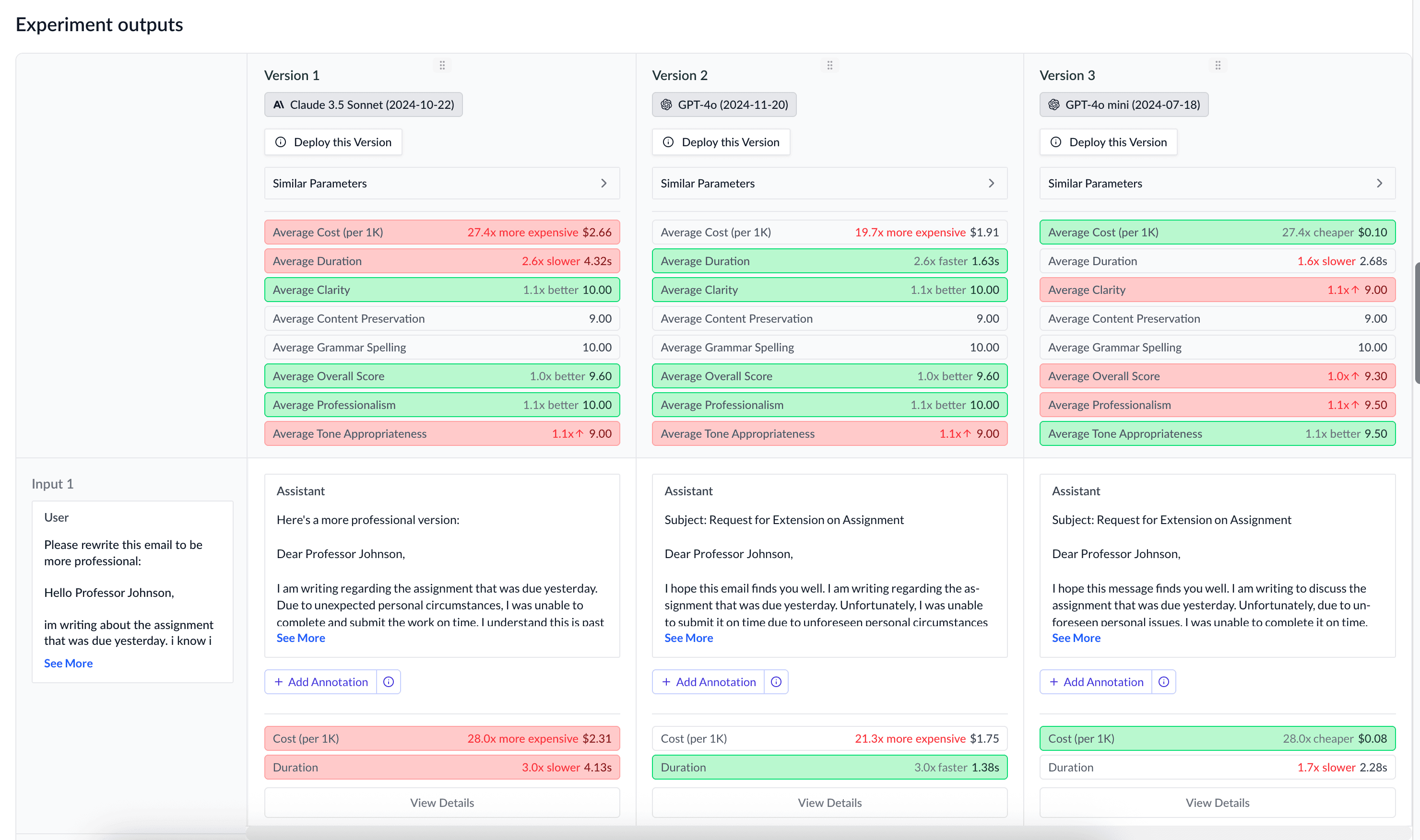
You can then ask your AI coding agent to analyze these evaluation results by querying the annotations:
Which model configuration of email-summarizer performed best overall according to the judge?What were the most common issues the judge found in the email summaries?How is this guide?
Using Annotations to Improve Agents
Learn how to use annotations to provide specific feedback on completions and experiments, enabling your AI coding agent to improve your agents based on real-world performance
Debugging Agent Issues
Step-by-step guide to identifying, analyzing, and resolving issues with your AI agents by utilizing your AI assistant's debugging capabilities